TL;DR (Summary)
Traditional image watermarking methods struggle to handle scenarios where only small portions of an image are watermarked. The Watermark Anything Model (WAM) redefines watermarking as a segmentation task, introducing a method to embed and extract watermarks localized to specific areas of an image. This approach enables robust watermarking for complex scenarios, such as splicing or AI-generated content, and allows extraction of multiple distinct watermarks from small regions of an image.
How does it work?
The Problem
Conventional watermarking treats images as a whole, leading to difficulties in:
- Detecting watermarks in spliced or edited images, where the watermarked area is small (padding or outpainting),
- Extracting multiple watermarks within one image (if one image is a combination of two images, generated with different watermarked AI generators for instance).
Watermark Anything Model (WAM)
WAM uses a deep learning-based embedder and extractor to:
- Embed watermarks into an image in a way that is imperceptible,
- Segment the image in watermarked and non-watermarked areas, and extract one binary message per pixel. These pixel-wise messages can later be used to retrieve groups of messages inside the image with a clustering algorithm (DBSCAN).
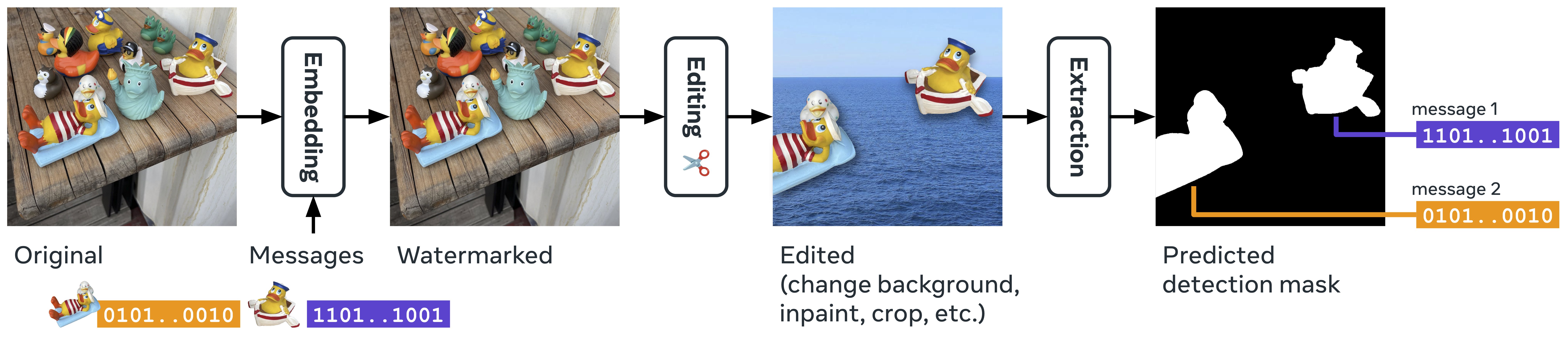
Key Features
- Imperceptibility: The image modification is done in textured areas of the image by modulating the distortion by a just noticeable difference map (JND);
- Segmentation Task: Detects specific parts that are watermarked (therefore allowing us to know which part have been edited);
- Robustness: Handles severe augmentations like cropping, inpainting, and splicing;
- Multiple watermarks: Extracts distinct messages from up to 10% of an image’s surface.
Main Results
WAM outperforms state-of-the-art methods in terms of:
- Robustness: Maintains watermark bit accuracy under heavy augmentations (e.g., cropping, resizing, JPEG compression);
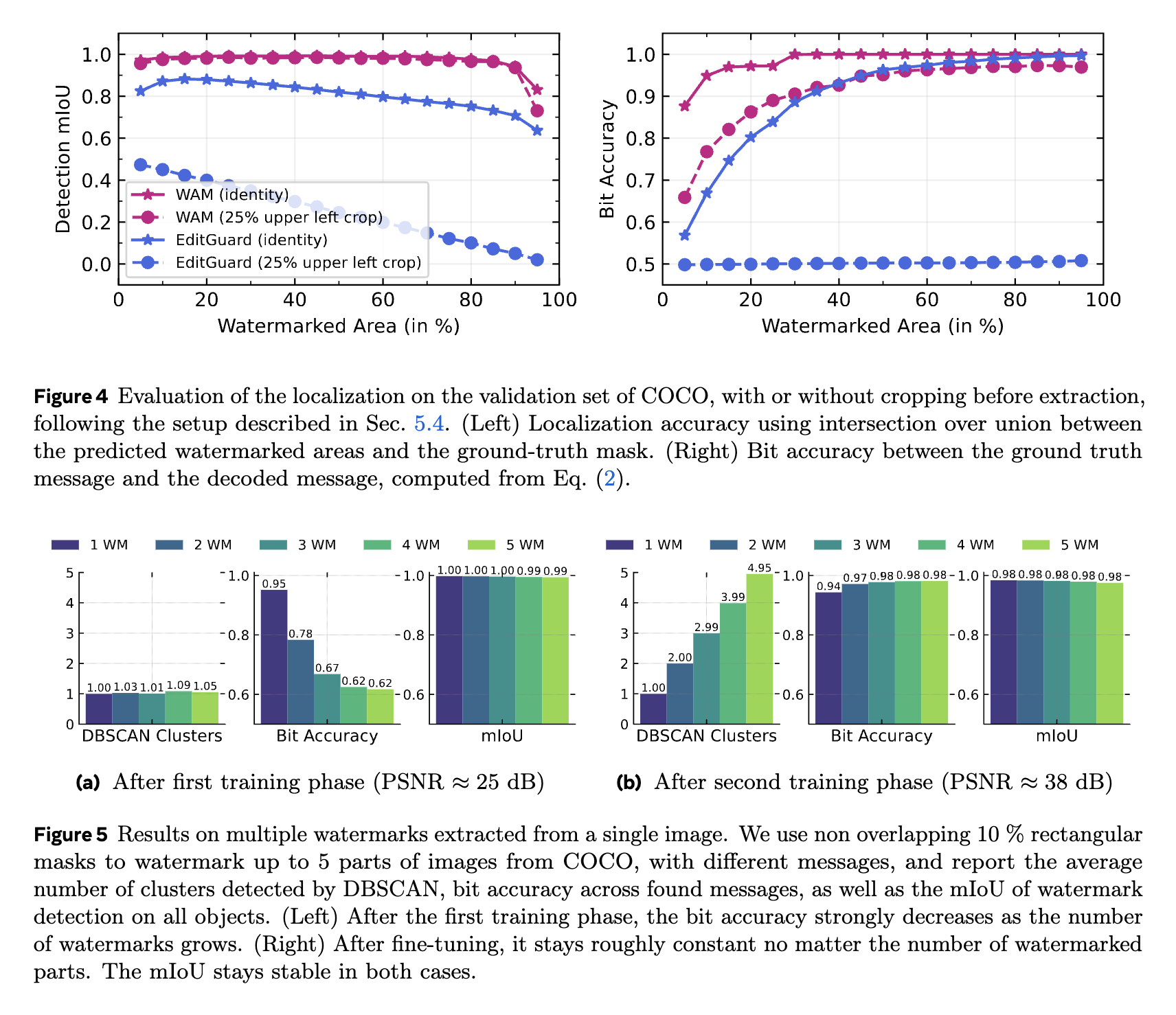
- Localization: Accurately detects watermarked areas and recovers up to 95% of bits from spliced or heavily edited images;
- Multiple messages: While offering the capability to trace different mesages inside the same image.
Method Details
Two-Phase Training Process
- Robust pre-training: Focuses on embedding watermarks resistant to image augmentations. Jointly trains the embedder and the extractor at very low PSNR (high image distortion).
- Fine-tuning for imperceptibility and multiple messages: Optimizes watermarks to be invisible to the human eye while preserving robustness. We add the JND modulation and creates transformations where the transformed image contains several watermarks.
Architecture Highlights
- Embedder: Adds a hidden message as a low-visibility signal in the image. Based on the VAE of Stable Diffusion.
- Extractor: Uses a segmentation-like model to decode embedded messages from specific image regions. Based on the ViT from Segment-Anything.
Why is WAM Important?
With regulatory acts (e.g., EU AI Act, US AI Governance) requiring the identification of AI-generated content, WAM provides a practical solution by enabling localized, robust, and multi-message watermarking. It is especially valuable for:
- Content attribution in AI-generated media.
- Tracking and identifying specific edits in mixed or manipulated content.
- Enhanced copyright protection and tamper localization.
Slides