TL;DR (Summary)
We introduce AudioSeal, a SOTA proactive solution for the detection of voice cloning or speech generation, based on a first-of-its-kind localized watermarking.
It beats passive detection methods by a huge margin. Compared to other watermarking methods, AudioSeal is perceptually better, has better robustness against edits and is ultra fast (can be used in real-time applications). And AudioSeal is pip installable!
Towards better traceability of AI-generated speech with watermarking
The rise of AI-generated content poses challenges in ensuring authenticity and trustworthiness. Voice cloning, in particular, has the potential to deceive and manipulate individuals through the creation of synthetic voices that mimic real ones. Detection of these contents is at the same time crucial, to prevent their misuse and getting harder as the quality of the generated content improves.
To address this issue, we developed AudioSeal, a cutting-edge solution that leverages localized watermarking to detect AI-generated speech with precision. Instead of relying on passive detection, AudioSeal proactively embeds a watermark into the speech signal, which can be later detected to verify the authenticity of the content. The particularity of AudioSeal is that the watermark detection is localized. The detector directly predicts for each time step (1/16k of a second) if the watermark is present or not, which makes it ultra fast and suitable for real-time applications.
Previous iterations of AudioSeal were used to watermark generative models in public demos from AI at Meta, such as Audiobox and Seamless, serving 100k users daily.
How does it work?

AudioSeal consists of two main components:
- A generator, which generate an additive watermark waveform based on the input audio,
- A detector, which predicts the presence of the watermark at each time step.
The generator is trained to produce a watermark that is imperceptible to the human ear, and robust to common audio processing operations such as compression, re-encoding, and noise addition. The detector is trained to predict the presence of the watermark at each time step, and is designed to be fast and suitable for real-life applications where watermarked audio is embedded in a stream of (often non-watermarked) audio.
Model training
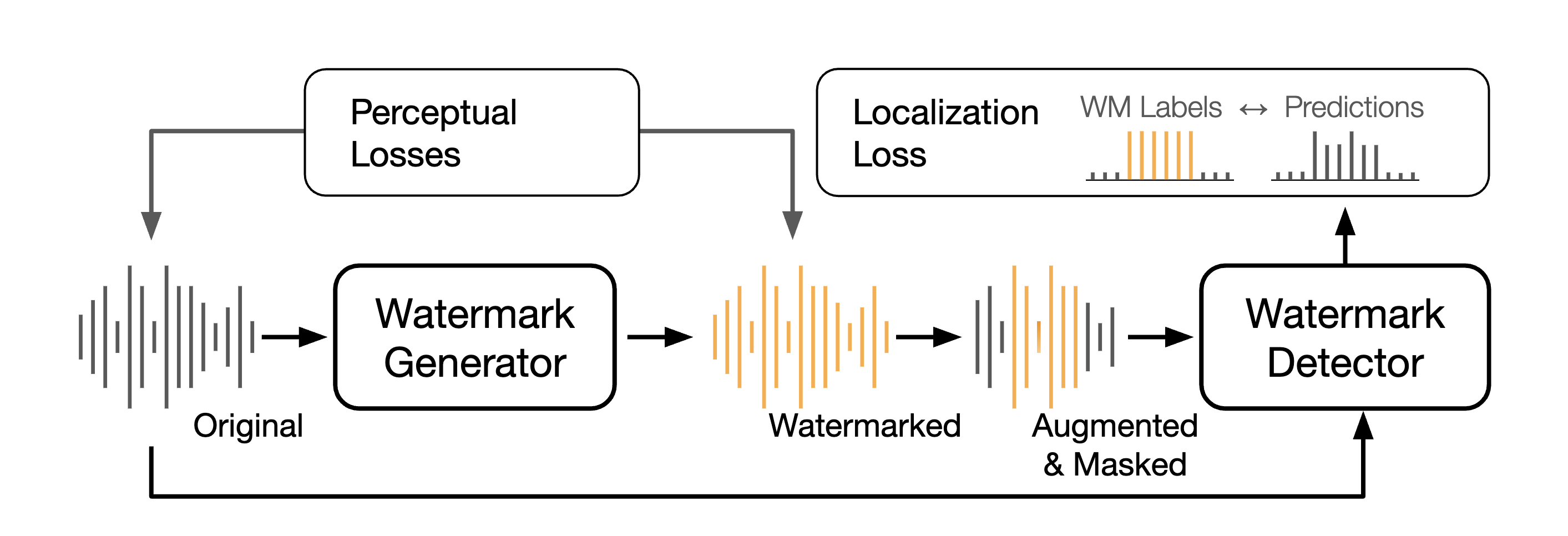
The training of AudioSeal involves a joint optimization of the generator and detector models.
-
The generator takes an audio waveform as input and outputs a watermark waveform of the same dimensionality. This watermark is then added to the original audio to create the watermarked audio.
-
To ensure robustness against audio editing and precise localization of the watermark, we employ a collection of training time augmentations. These include random masking of the watermark with silences and other original audios, as well as a range of signal alterations such as bandpass filtering, audio boosting, adding echo, noise, etc.
-
The detector model processes the original and watermarked signals, outputting a soft decision at every time step. The detector is trained to maximize its accuracy while minimizing the perceptual difference between the original and watermarked audio.
We optimize two classes of functions: perceptual loss functions, which measure the perceptual difference between the original and watermarked audio, and detection loss functions, which measure the difference between the detector’s output and the ground truth. They make sure that the watermark is both imperceptible and robust to audio editing. We also extend AudioSeal to support multi-bit watermarking, allowing an audio to be attributed to a specific model or version without affecting the detection signal.
Model architectures
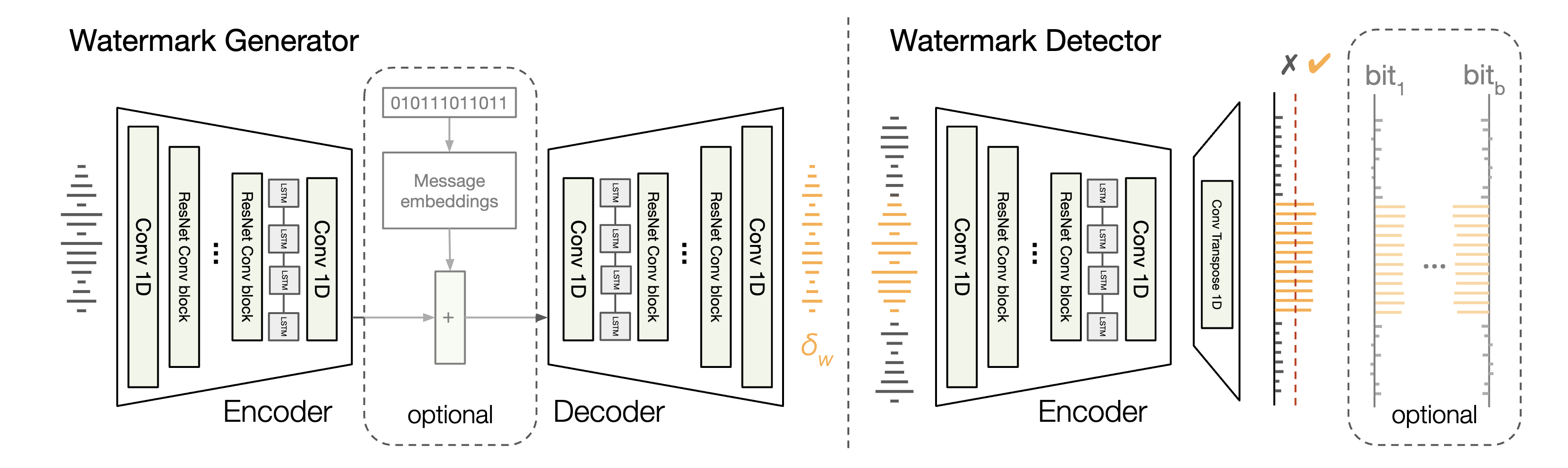
The architecture of the generator and detector models is based on the EnCodec design. The generator consists of an encoder and a decoder, both incorporating elements from EnCodec. The encoder applies a 1D convolution followed by four convolutional blocks, each including a residual unit and down-sampling layer. The decoder mirrors the encoder structure but uses transposed convolutions instead.
The detector comprises an encoder, a transposed convolution, and a linear layer. The encoder shares the generator’s architecture but with different weights. The transposed convolution upsamples the activation map to the original audio resolution, and the linear layer reduces the dimensions to two, followed by a softmax function that gives sample-wise probability scores.
Detection, Localization, Attribution
The detector is designed to predict the presence of the watermark and optional bits at each time step. For instance, for an audio where the watermark is present between 5s and 7.5s, the detector probability output will look like:
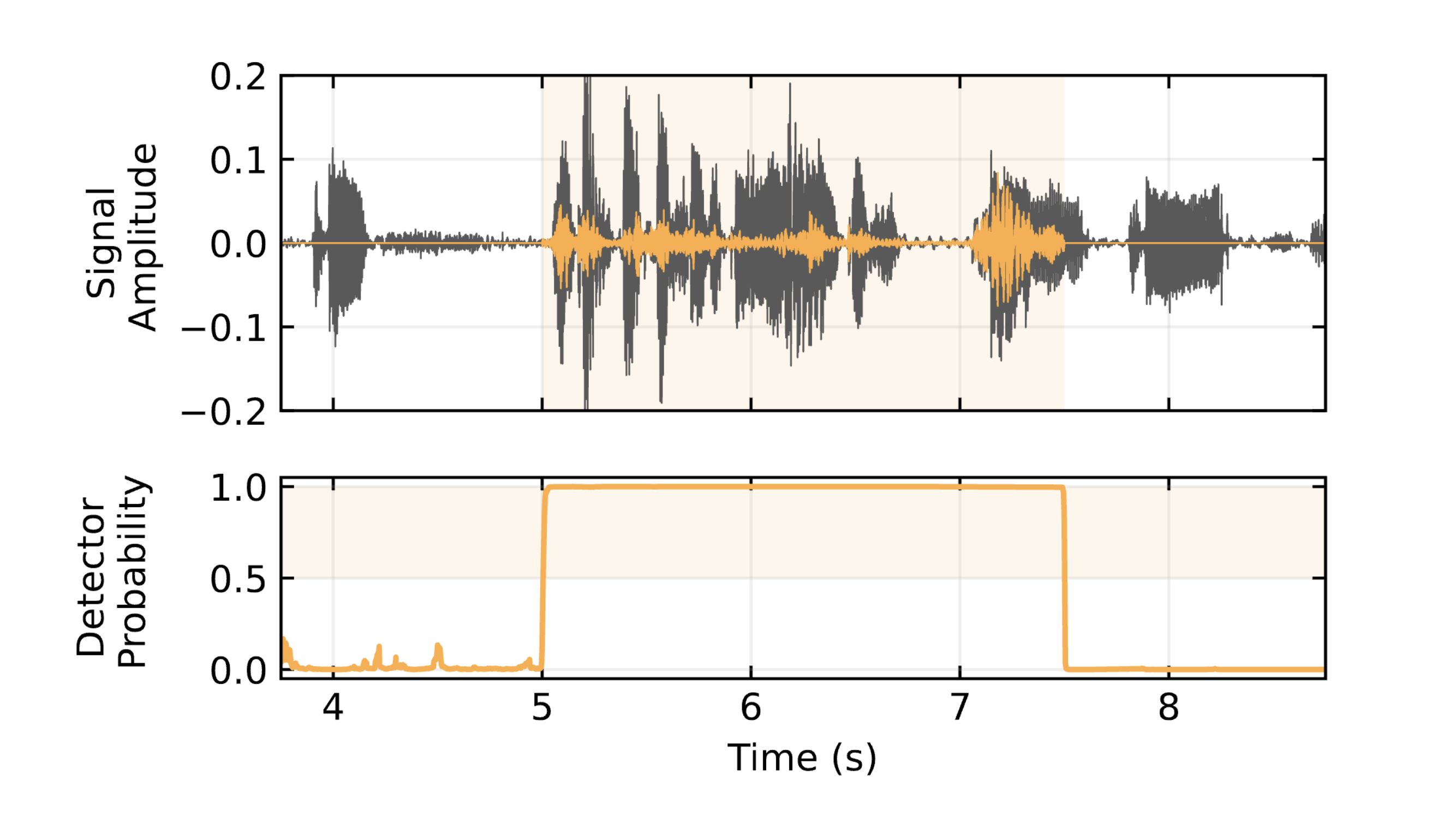
This allows for:
- Detection: we use a threshold on the average detector’s output to decide if the watermark is present or not.
- Localization: we use a threshold on the detector’s output to decide if the watermark is present at each time step.
- Attribution: we use the optional bits to attribute the audio to a specific model or version.
Main results
Examples
Here are some examples. Each pair consists of an original audio and its watermarked counterpart.
Original Audio
Watermarked Audio
Here are some other examples from a music dataset:
Original Audio
Watermarked Audio
and from an environmental sounds dataset:
Original Audio
Watermarked Audio
The watermark is also detectable when music is added to the audio in the background of a watermarked speech:
Watermarked Speech
Watermarked Speech + Music (detected)
Compared to passive detection
AudioSeal significantly outperforms passive detection methods, achieving near-perfect detection rates over a wide range of audio edits. In contrast, passive detection methods, which do not alter the audio source, are prone to fail as generative models advance and the difference between synthesized and authentic content diminishes.
Compared to the current SOTA watermarking method
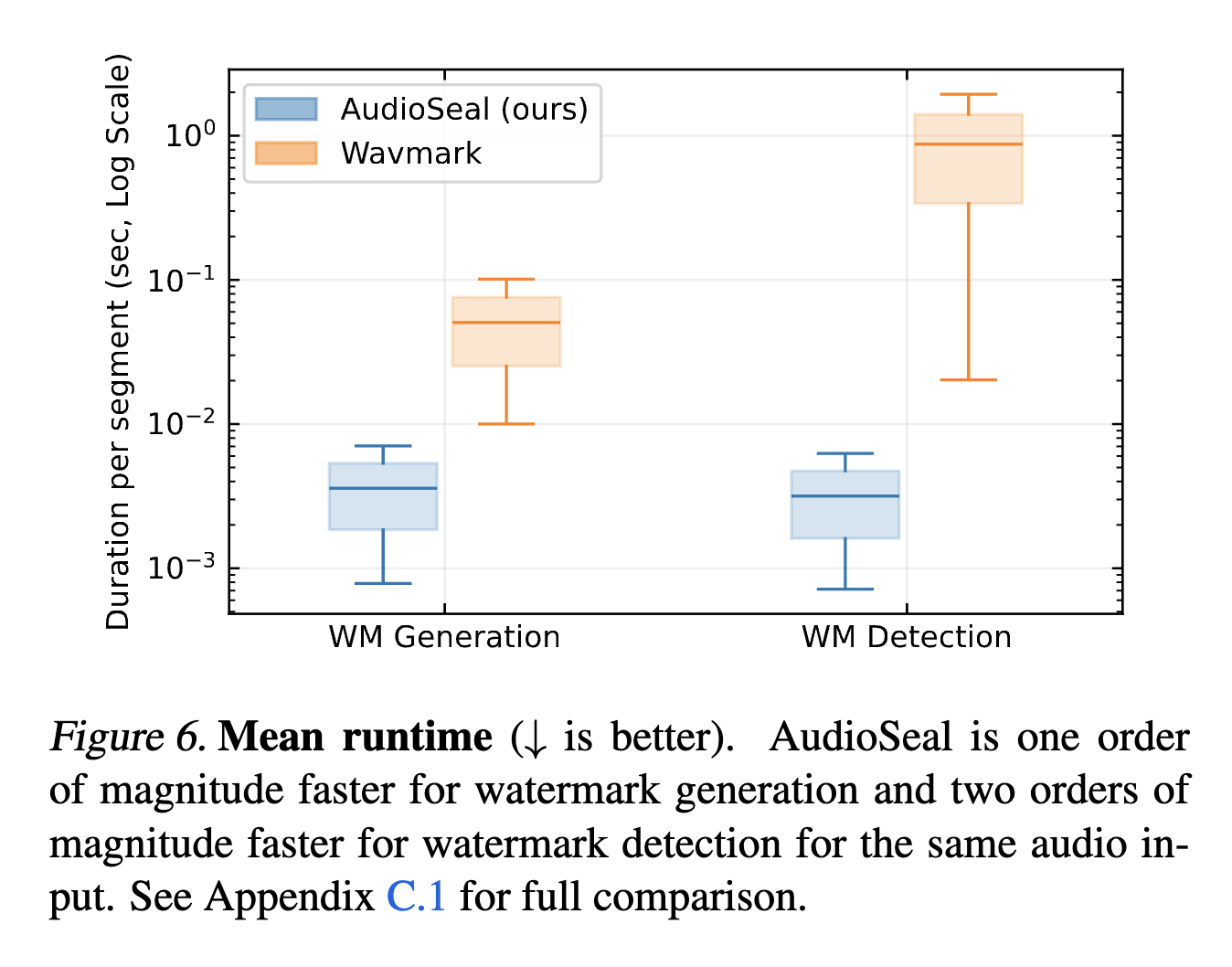
Compared to the current state-of-the-art watermarking method, WavMark, AudioSeal achieves better perceptual quality, higher robustness to various audio editing techniques, and significantly faster detection speed (up to 1000x faster). This is particularly important for real-time and large-scale applications where most content is not watermarked.

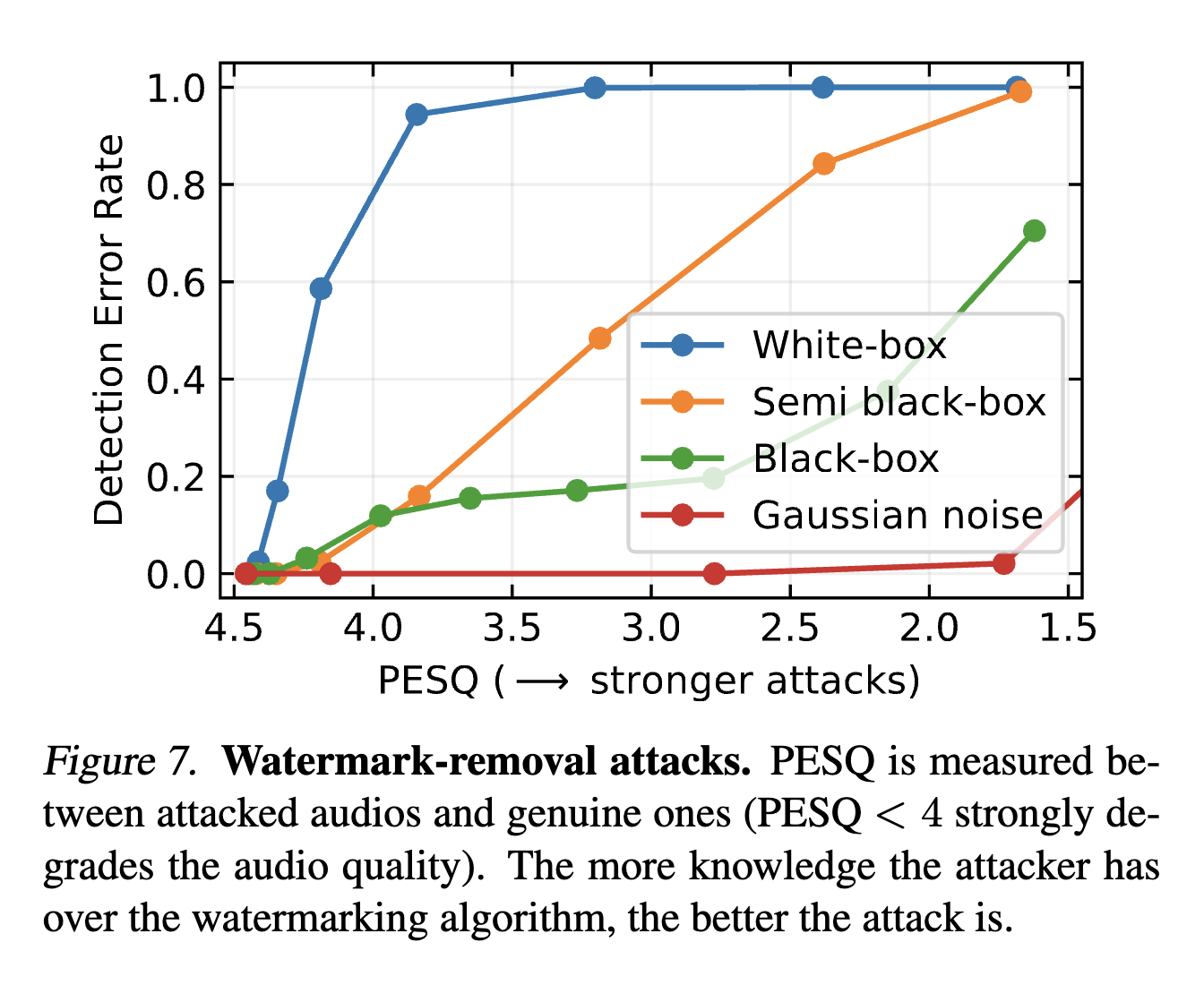
Watermark robustness to attacks
We also evaluated the robustness of AudioSeal to various adversarial attacks:
- white-box attacks against the detector,
- semi black-box by retraining other generators/detectors pairs, and attacking the new detector,
- black-box attacks by training a classifier to distinguish watermarked from non-watermarked audio, and using it as proxy to attack the detector.
Our findings suggest that the more information is disclosed about the watermarking algorithm, the more vulnerable it is.
Conclusion
AudioSeal represents a significant advancement for audio content detection, offering a proactive solution to combat the proliferation of AI-generated content. As technology continues to evolve, innovative approaches like AudioSeal play a crucial role in safeguarding the integrity of audio content and upholding responsibility in the deployments of these generative models.